
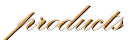 你的位置:幸运彩app2026世界杯中国官方下载 > 幸运彩首页 > 幸运彩app2026世界杯中国官方下载 AI收获单背后, 藏着一位华东说念主“出题东说念主”
你的位置:幸运彩app2026世界杯中国官方下载 > 幸运彩首页 > 幸运彩app2026世界杯中国官方下载 AI收获单背后, 藏着一位华东说念主“出题东说念主”


每次前沿模子发布,AI圈皆会盯着几张熟识的收获单。
MMLU-Pro、MMMU、MMMU-Pro……这些名字对粗莽用户来说有些生疏,但对模子公司和权衡者而言,它们险些也曾成了“尺度科目”。GPT、Claude、Gemini、Llama、Qwen、DeepSeek们不休在这些基准上交卷。
“是骡子是马拉出来溜溜”,模子怎样样,时常皆要靠这些分数来证明。
许多模子发布会上的性能对比图,离不开它们;HuggingFace上的一些排名榜,也设立在这些评测体系之上。以致不错说,今天AI行业盘考模子智商时,使用的也曾是一套由这些基准界说的共同语言。
但挑升旨真义的是,险些扫数东说念主皆在蔼然分数,却很少有东说念主知说念出题的东说念主是谁。而MMLU-Pro、MMMU和MMMU-Pro背后,皆能看到吞并个名字——陈灯谜。
他是加拿大滑铁卢大学算计机科学系助理讲解,在谷歌学术上,他的论文被援用越过3万次。
他亦然“老虎本质室(TIGERLab)”的首创东说念主,这个本质室的英文全称是Text and Image GEnerative Research Lab,因为名字里有一个“虎”字,陈灯谜为其起了一个很有辨识度的汉文名——虎头帮。
01
旧考卷失灵之后
陈灯谜来源被更多东说念主防止到,是因为MMLU-Pro。
MMLU也曾是大语言模子智商评估中最常用的基准评测之一。它像一张空洞试卷,遮盖多个学科,用来权衡模子在常识交融和推理任务上的弘扬。
在早期,这张卷子很有效。模子之间的差距能被分数拉开,行业也不错通过它不雅察大语言模子是不是真的在进取。
但问题很快出现了。
跟着模子智商不休提高,MMLU逐步变得“不够考”了。前沿模子的分数越来越高,彼此之间的差距越来越小。
到OpenAI发布o3之后,这个问题变得愈加赫然。o3在MMLU上的准确率也曾接近100%,其他前沿模子也接续交出迫临满分的收获。
这听起来像是一个好音讯,但对评估来说,反而意味着阻挠。
一张试卷淌若大家皆能考接近满分,就很难络续判断谁更强、强在那儿。它仍然不错证明模子也曾具备某些智商,却不再符合权衡新的进取。
AI行业需要一张更难、也更退却易被“乱来畴前”的卷子。
2024年,陈灯谜和团队推出了MMLU-Pro。
MMLU-Pro从头矫正了这张考卷,而非浅易把题库扩大。
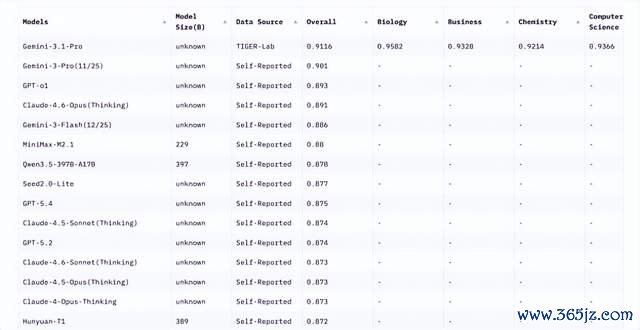
它包含12032说念题,遮盖数学、物理、化学、法律、工程、面目学、健康等14个限度。比较原版MMLU,它把选项从4个扩张到10个,镌汰模子靠推测蒙对的概率;同期加入更多偏推理的问题,计帐掉原题库中相对浅易、存在歧义玩忽分别度不及的题目。
后果很径直。
论文放胆骄横,模子在MMLU-Pro上的准确率比较原版MMLU下落了16%到33%。吞并模子在24种不同教唆词格调下测试时,收获波动也从原MMLU的4%到5%,下落到约2%。
也就是说,这张新卷子不仅更难,也更理会。
它让那些在旧考卷上看起来皆很优秀的模子,从头被拉开了差距。模子到底是真会推理,如故只是更擅长应酬旧题,也因此更容易被看出来。
02
好用的基准评测
斗鱼体育app中国官网下载MMLU-Pro很快被行业拿去用了。
MMLU-Pro随后投入NeurIPS2024数据集与基准评测赛说念,也被EleutherAI的语言模子评测框架lm-evaluation-harness集成。对开源模子社区来说,这意味着它不再只是一篇论文里的数据集,而是投入了常用评测器用链。
许多模子发布时,运行申诉MMLU-Pro分数。HuggingFace上的一些排名榜,也把它纳入评估体系。
淌若说MMLU-Pro处罚的是语言模子评估里的“旧考卷失灵”,那么MMMU则把陈灯谜和TIGERLab推到了多模态评测的中心。
多模态模子的问题更复杂。
语言模子答题,主要处理翰墨。多模态模子则要同期处理图片、图表、知道图、舆图、表格、曲谱、化学结构等不同形势的信息。它不单是要读懂题干,还要的确看懂图像里的本色,并把视觉信息、文本信息和学科常识放在沿路推理。
MMMU基准评测包含1.15万说念多模态问题,来自得学考试、锤真金不怕火和讲义,遮盖艺术与操办、买卖、科学、健康与医学、东说念主文社科、时代与工程六大限度,进一步细分为30个学科和183个子限度。
这些题目不是浅易问模子“图里有什么”,幸运彩app它条目模子像学生作念专科题同样,把图像信息和学科常识集中起来。
MMMU发布时,权衡团队测试了14个开源多模态模子,以及GPT-4V、GeminiUltra等代表性闭源模子。即即是那时最强的闭源模子,GPT-4V和GeminiUltra也只达到56%和59%的准确率。
这组数字阐发,多模态模子看起来进取很快,但在的确需要专科交融和推理的问题上,仍然有巨额空间。
自后,陈灯谜团队又推出了MMMU-Pro,进一步堵住模子绕过视觉信息的空间。它过滤掉只靠文本模子也能回话的问题,扩张候选项,并引入vision-only设立,把问题镶嵌图像中,条目模子同期完成视觉读取和文本交融。
浅易说,就是不让模子“只看翰墨猜谜底”。
这类责任听起来颇有点琐碎之感,但它们很关键。因为多模态模子将来要投入医疗、栽培、科研、操办、工程等场景,只是能面目图片是不够的。它必须能判断、推理、解释,也必须能在复杂视觉信息中找到的确有效的部分。
03
“考卷”背后的东说念主
陈灯谜自后作念MMLU-Pro和MMMU,来自于他一直以来的权衡所在。

他的权衡有趣有趣蓝本就与复杂信息交融、常识问答和推理相关。
他本科毕业于华中科技大学,之后到德国亚琛工业大学攻读硕士,再到加州大学圣巴巴拉分校赢得算计机科学博士学位。博士时辰,他也曾运行围绕复杂问答、表格推理、常识左证定位等所在作念权衡。
这类任务有一个共同点:谜底时常不在单一文本里。
它可能藏在一张表格里,也可能需要集中一段翰墨和一张图片,还可能需要模子先检索信息,再整合、算计和推理。模子不成只会复述已有常识。
陈灯谜参与过的HybridQA、TabFact、ProgramofThoughts、MAmmoTH等技俩,皆和这条线相关。
这也解释了他为什么会对模子评估里的罅隙明锐。
好的基准评测不是浅易把题目搞得越来越难,而是要预判模子最容易在那儿“蒙对题”“看起来会”。
模子可能记取了题库,也不错靠选项猜谜底,还可能用翰墨绕过视觉信息……好的评估得把这些罅隙补好。
博士毕业后,陈灯谜投入谷歌权衡院,随后在2021年至2025年参与谷歌DeepMind的Gemini多模态模子和评估责任。这段阅历也很贫窭。恒久战役前沿模子研发,让他更明晰模子智商是怎样增长的,也更容易看见评估中可能存在的偏差和盲区。
2022年秋季,陈灯谜加入滑铁卢大学算计机科学学院,担任助理讲解。同庚,他入选CanadaCIFARAIChair。之后,他创办“老虎本质室(也就是虎头帮)”,络续围绕基础模子、多模态智商和基准评测伸开权衡。

虎头帮并不单是作念基准评测,也在作念模子和系统权衡。
在视频方进取,UniVideo试图把视频交融、生成和剪辑放进吞并个框架,让模子不单是生成一段画面,也能交融本色、反应指示并完成修改。Vamba对准长视频交融,处罚一小时级别视频带来的显存、算计和教养效用问题。与Meta生成式AI团队配合的MoCha,则把要点放在话语臆造变装生成上,通过语音和翰墨面目生成高质地东说念主物视频。

一个从来不作念题的出题东说念主是不可能出好题的。我方下场作念模子,反过来也让他们更符合作念评估。
因为真偶合的评估,时常来自对模子智商规模的交融。独一知说念模子是怎样作念出来的,知说念它在真实任务里会际遇什么问题,才更容易操办出能测出差距、也能显现问题的题目。
如今,陈灯谜投入Meta超等智能本质室,责任络续集聚在多模态预教养数据和评估,并行状于Meta基础模子。
AI行业并不空泛被看见的东说念主。AI行业里,聚光灯时时会落在创业者、明星权衡员和大模子公司的细腻东说念主身上。新址品发布、融资音讯、开源模子和团队转移,时常最容易劝诱外界蔼然,也让这些名字更容易投入公众视线。
但今天的AI限度幸运彩app2026世界杯中国官方下载,华东说念主东说念主才的参与也曾远不啻这些最显眼的位置。
 备案号:
备案号: